话说昨天想整理一篇人人都是产品经理网站上的文章,然而,里面全是图片,于是想写个爬虫把他们爬下来。
可是就在我查看网页源代码的时候,问题来了:

纳尼??中文???
好吧其实我第一次尝试的时候是忽略中文了,直接使用如何用爬虫抓取图片里面的代码进行爬取。当然,结果就是报错,报错,报错。。。。。
于是问了下伟大的度娘,得到的一些方法都不行,比如import sys什么什么的……(会不会跟我是python3有关系?)
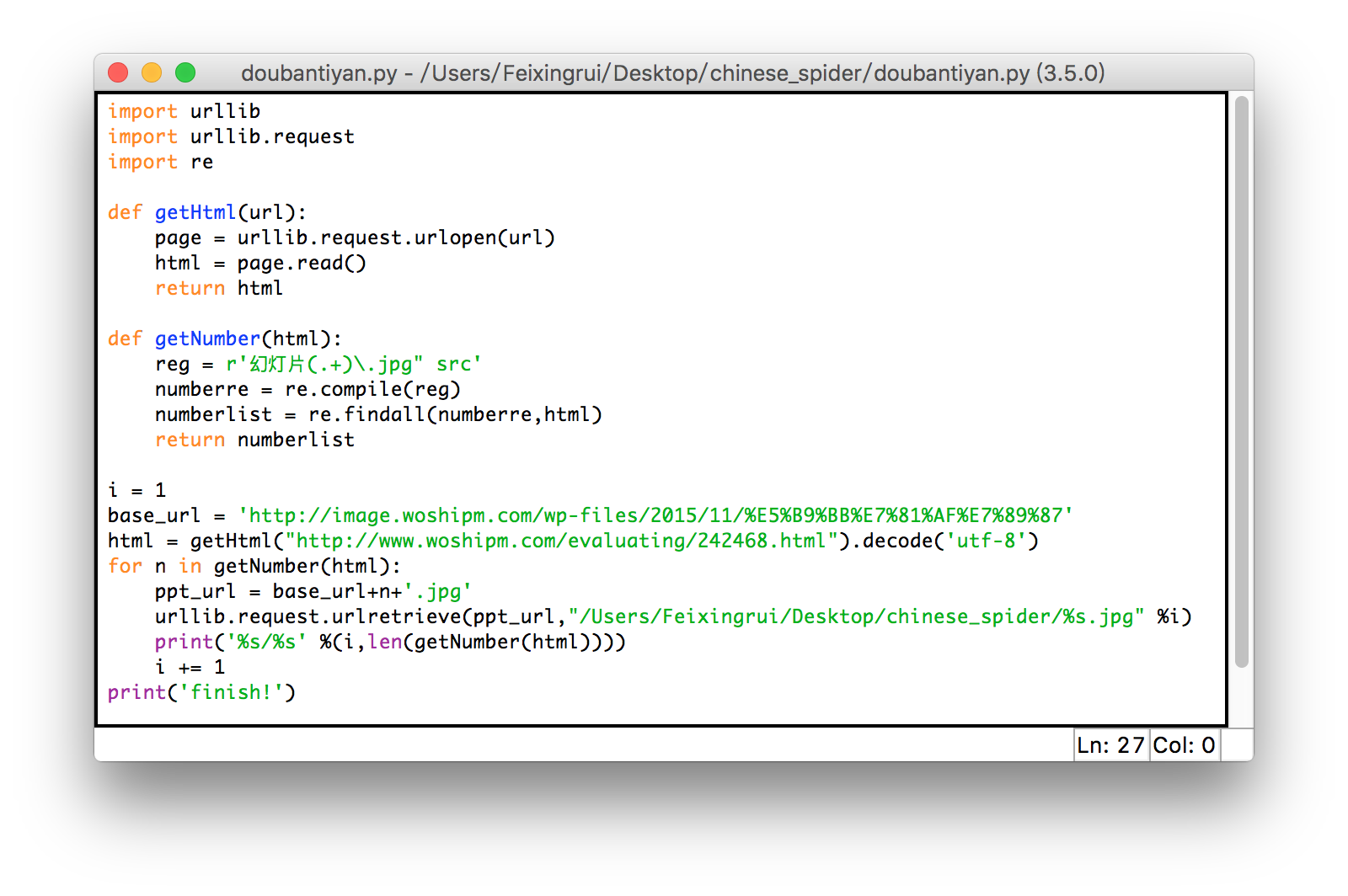
不管了,问题不解决睡不着啊!怎么办怎么办?于是我想到了一个讨巧的办法“拼接URL”!!!
因为我想到了中文是可以进行URL编码的!!!
百度(动词)URL在线编码,输入【幻灯片】,点击编码,即可得到【%E5%B9%BB%E7%81%AF%E7%89%87】
再然后就不用我教了吧~~~
本文由www.feixingrui.com原创,转载请注明出处。
技术改变世界~

excellent article.
Thank you ~
麻烦问下,我用了你说的转码,为啥还是报错呢Exception “unhandled UnicodeDecodeError”
‘utf-8’ codec can’t decode byte 0xb6 in position 107431: invalid start byte
是不是页面不是utf-8编码?